
本文翻译自@iamtrask的Anyone Can Learn To Code an LSTM-RNN in Python (Part 1: RNN)。本文作者已通过twitter联系作者,获得授权。
概要
我通过玩具代码一边学习一边调试能达到最好的学习效果。本文通过一个简单的python实现,教会你循环神经网络。
原文作者@iamtrask说他会在twitter上继续发布第二部分LSTM,敬请关注。
废话少说, 给我看看代码
|
|
运行时输出
|
|
第一部分:什么是神经元记忆
顺着背出字母表,你很容易做到吧?
倒着背呢, 有点难哦。
试着想一首你记得的歌词。为什么顺着回忆比倒着回忆难?你能直接跳到第二小节的中间么?额, 好像有点难。 这是为什么呢?
这其实很符合逻辑。 你记忆字母表或者歌词并不是像计算机把信息存储在硬盘上那样的(译者注:计算机可以随机访问磁盘。)。你是顺序记忆的。知道了前一个字母,你很容易知道下一个。这是一种条件记忆,只有你最近知道了前一个记忆,你才容易想起来下一个记忆,就想你熟悉的链表一样。
但是,并不是说你不唱歌的时候,歌就不在你脑子里了。而是说你如果想直接跳到中间那部分,你会发现很难直接找到其在脑中的呈现(也许是一堆神经元)。你想直接搜索到一首歌的中间部分,这是很难的, 因为你以前没有这样做过,所以没有索引可以指向歌曲的中间部分。 就好比你邻居家有很多小路, 你从前门进去顺着路走很容易找到后院,但是让你直接到后院去就不太容易。想了解更过关于大脑的知识,请看这里。
跟链表很像,记忆这样存储很高效。我们可以发现这样存储在解决很多问题时候有优势。
如果你的数据是一个序列,那么记忆就很重要(意味着你必须记住某些东西)。看下面的视频:
每一个数据点就是视频中的一帧。如果你想训练一个神经网络来预测下一帧小球的位置, 那么知道上一帧小球的位置就很重要。这样的序列数据就是我们需要构建循环神经网络的原因。那么, 神经网络怎么记住以前的信息呢?
神经网络有隐藏层。一般而言,隐藏层的状态由输入决定。所以,一般而言神经网络的信息流如下图:
这很简单直接。特定的输入决定特定的隐藏层,特定的隐藏层又决定了输出。这是一种封闭系统。记忆改变了这种状况。记忆意味着,隐藏状态是由当前时间点的输入和上一个时间点的隐藏状态决定的。
为什么是隐藏层而不是输入层呢?我们也可以这样做呀:
现在,仔细想想,如果有四个时间点,如果我们采用隐藏层循环是如下图:
如果采用输入层循环会是:
看到区别没,隐藏层记忆了之前所有的输入信息,而输入层循环则只能利用到上一个输入。举个例子,假设一首歌词里面有”….I love you…”和”…I love carrots…”,如果采用输入层循环,则没法根据”I love”来预测下一个词是什么?因为当前输入是love,前一个输入是I,这两种情况一致,所以没法区分。 而隐藏层循环则可以记住更久之前的输入信息,因而能更好地预测下一个词。理论上而言,隐藏层循环可以记住所有之前的输入,当然记忆会随着时间流逝逐渐忘却。有兴趣的可以看这篇blog。
第二部分:RNN - 神经网络记忆
现在我们已经有了一些直观认识, 接下来让我们更进一步分析。正如在反向传播这篇blog里介绍的,神经网络的输入层是由输入数据集决定的。每一行输入数据用来产生隐藏层(通过正向传播)。每个隐藏层又用于产生输出层(假设只有一层隐藏层)。如我们之前所说,记忆意味着隐藏层是由输入数据和前一次的隐藏层组合而成。怎么做的呢?很像神经网络里面其他传播的做法一样, 通过矩阵!这个矩阵定义了当前隐藏层跟前一个隐藏层的关系。
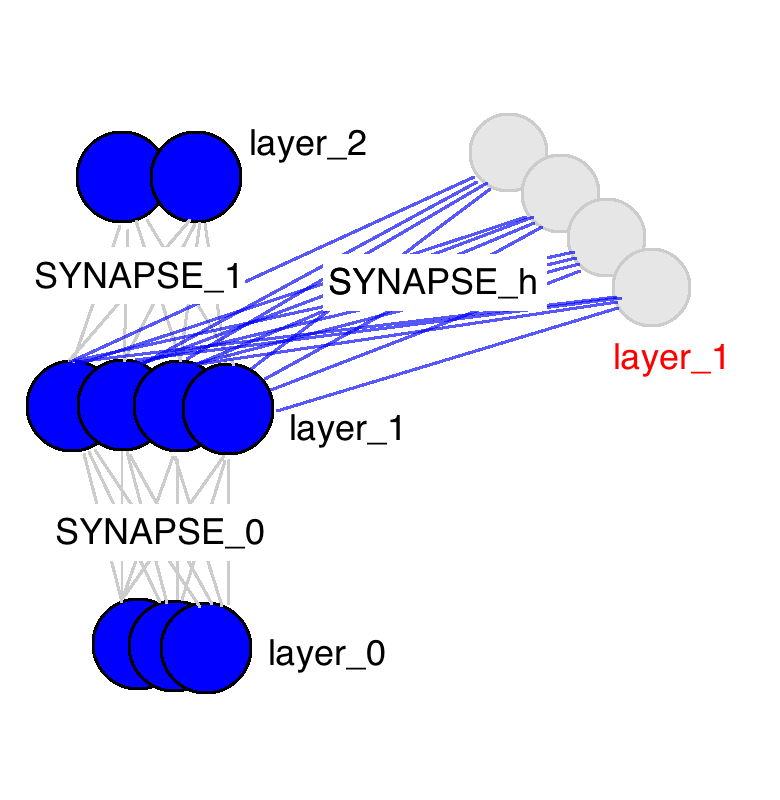
这幅图中很重要的一点是有三个权重矩阵。有两个我们很熟悉了。SYNAPSE_0用于把输入数据传播到隐藏层。SYNAPSE_1把隐藏层传播到输出数据。新矩阵(SYNAPSE_h,用于循环)把当前的隐藏层(layer_1)传播到下一个时间点的隐藏层(还是layer_1)。
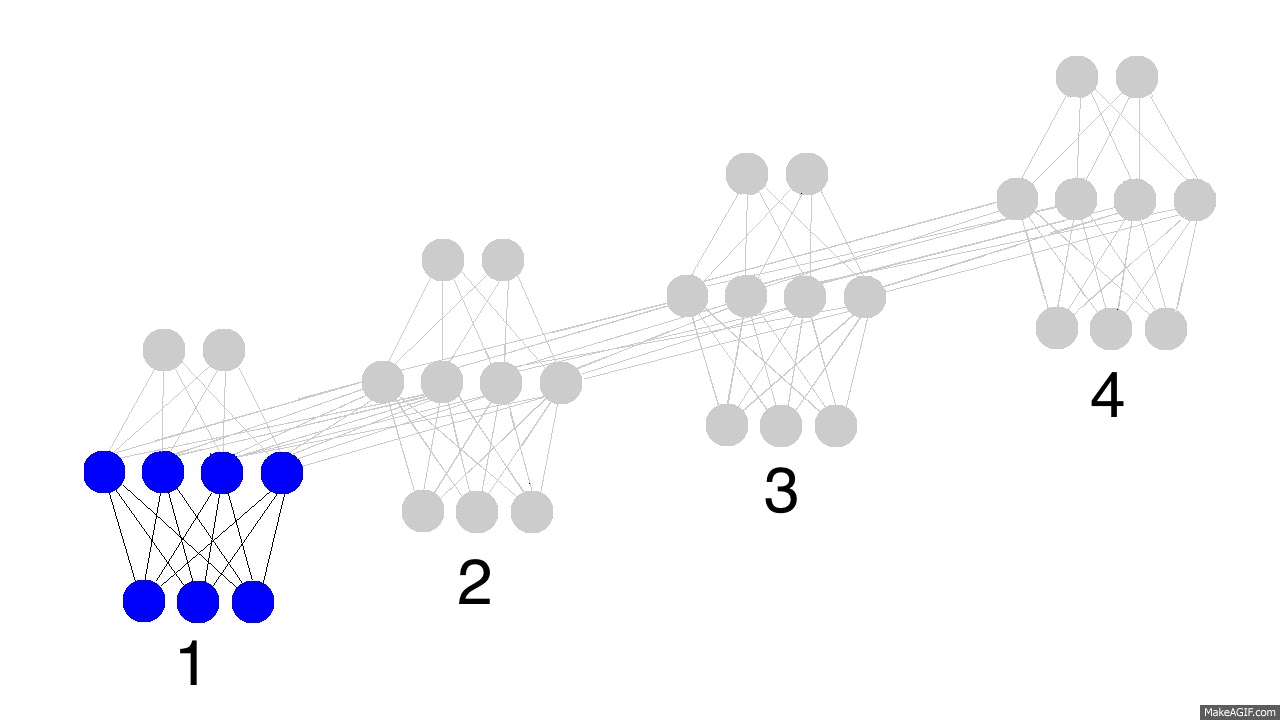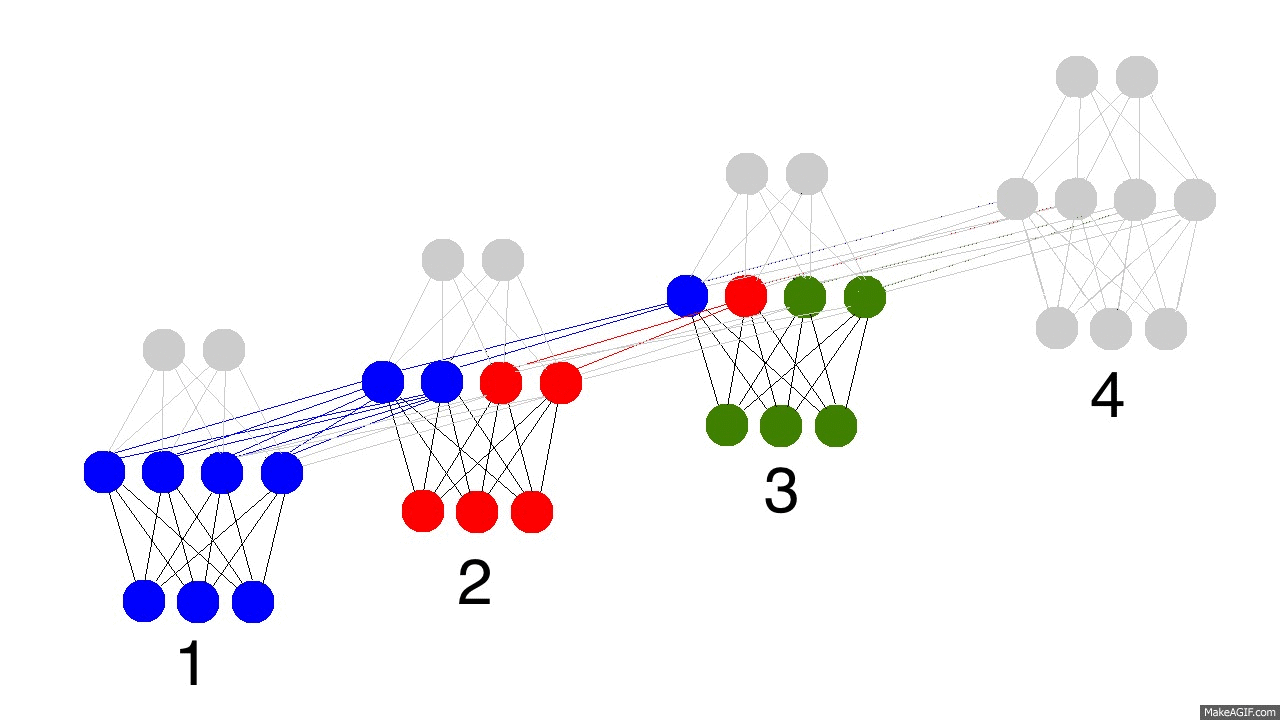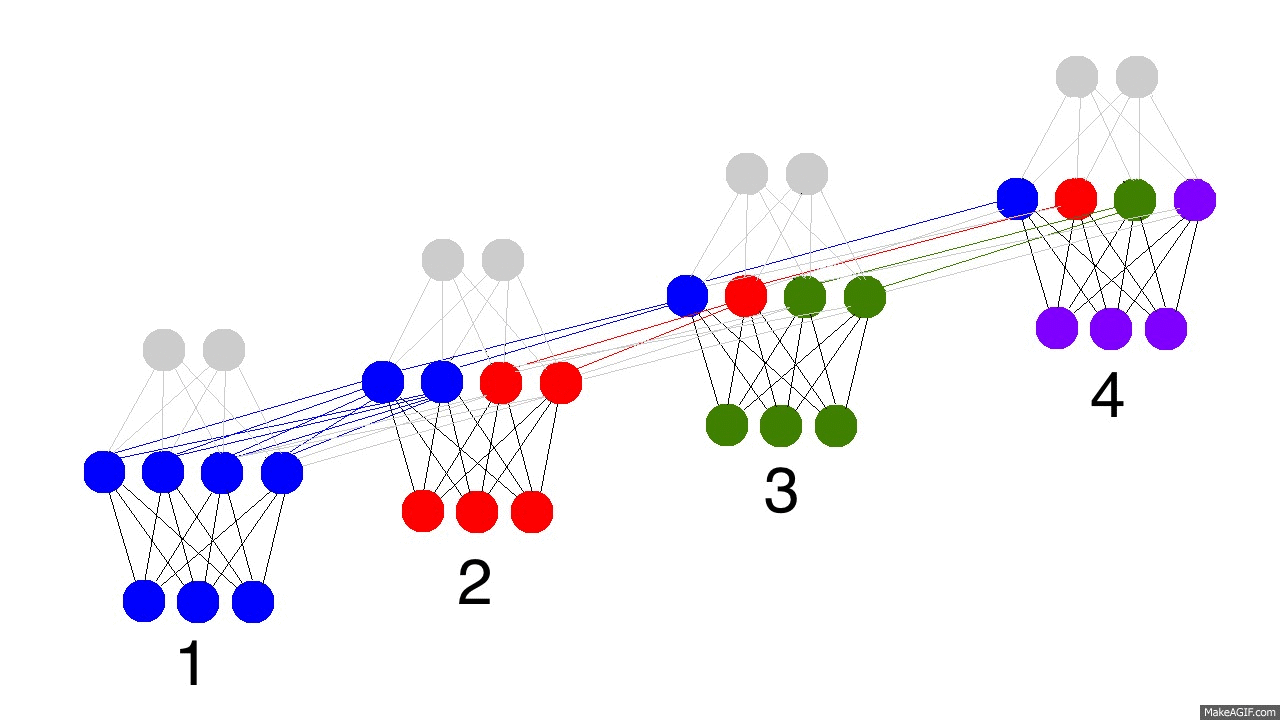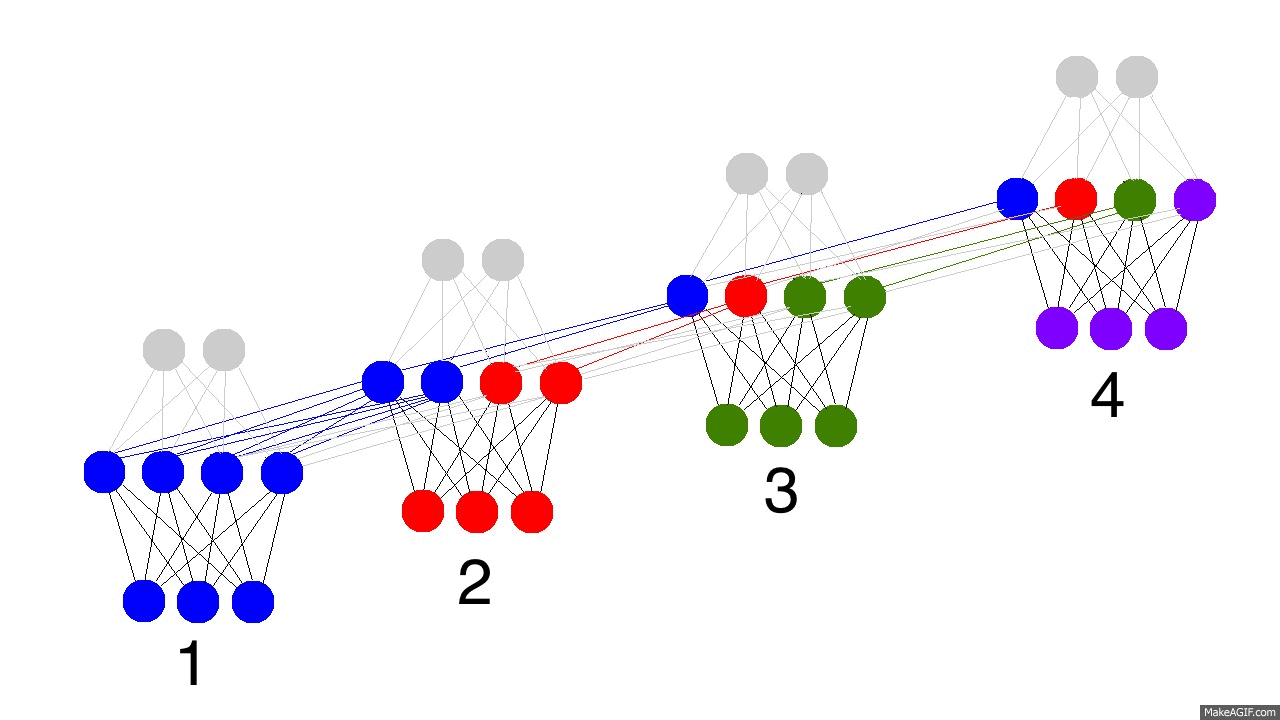
上面的gif图展示了循环神经网络的神奇之处以及一些很重要的性质。它展示了四个时间点隐藏层的情况。第一个时间点,隐藏层仅由输入数据决定。第二个时间点,隐藏层是由输入数据和第一个时间点的隐藏层共同决定的。以此类推。你应该注意到了,第四个时间点的时候,网络已经“满了”。所以大概第五个时间点来的时候,就要选择哪些记忆保留,哪些记忆覆盖。现实如此。这就是记忆“容量”的概念。如你所想,更大的隐藏层,就能记住更长时间的东西。同样,这就需要神经网络学会忘记不相关的记忆然后记住重要的记忆。第三步有没看出什么重要信息?为什么绿色的要比其他颜色的多呢?
另外要注意的是隐藏层夹在输入层和输出层中间,所以输出已经不仅仅取决于输入了。输入仅仅改变记忆,而输出仅仅依赖于记忆。有趣的是,如果2,3,4时间节点没有输入数据的话,隐藏层同样会随着时间流逝而变化。
第三部分:基于时间的反向传播
那么循环神经网络是怎么学习的呢?看看下面的图。黑色表示预测结果,明黄色表示错误,褐黄色表示导数。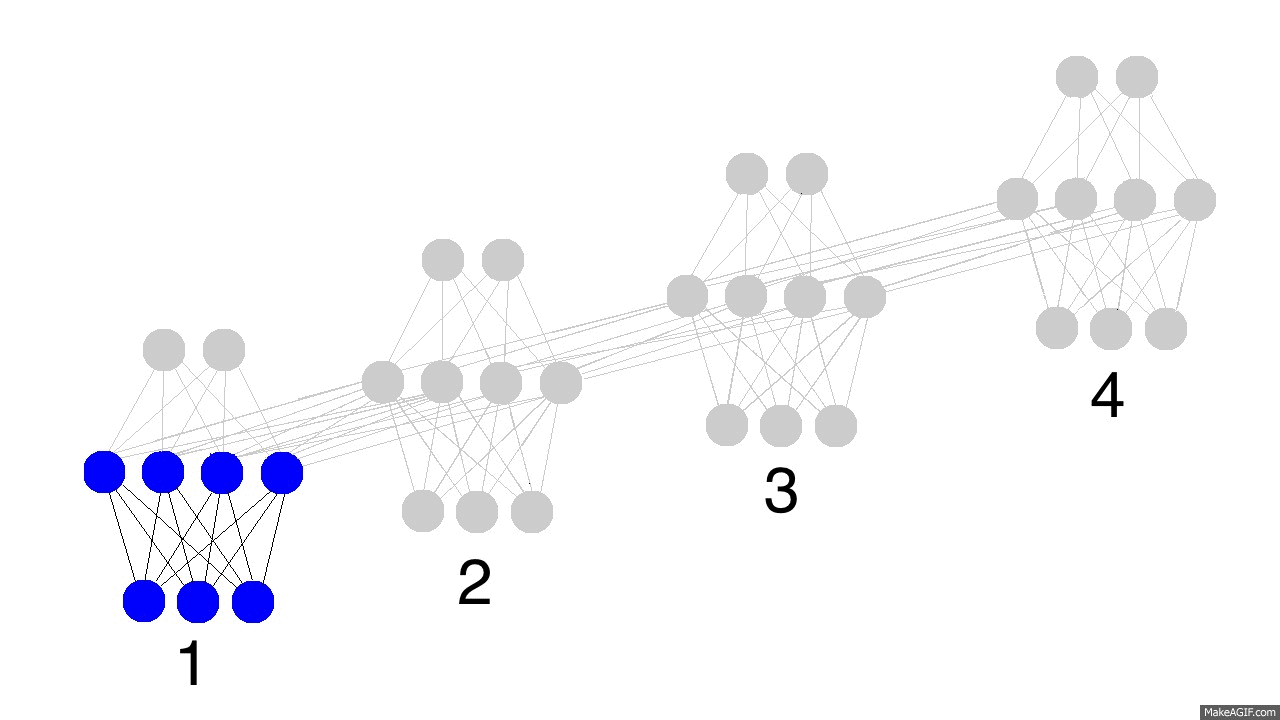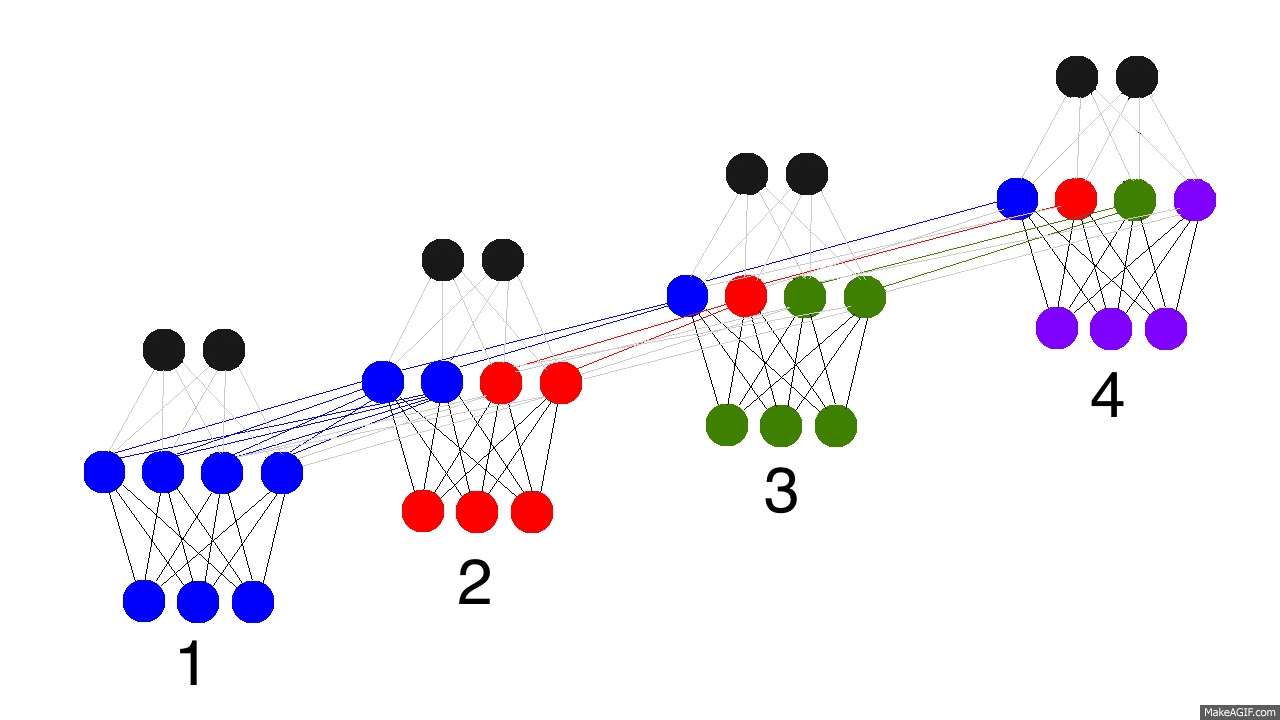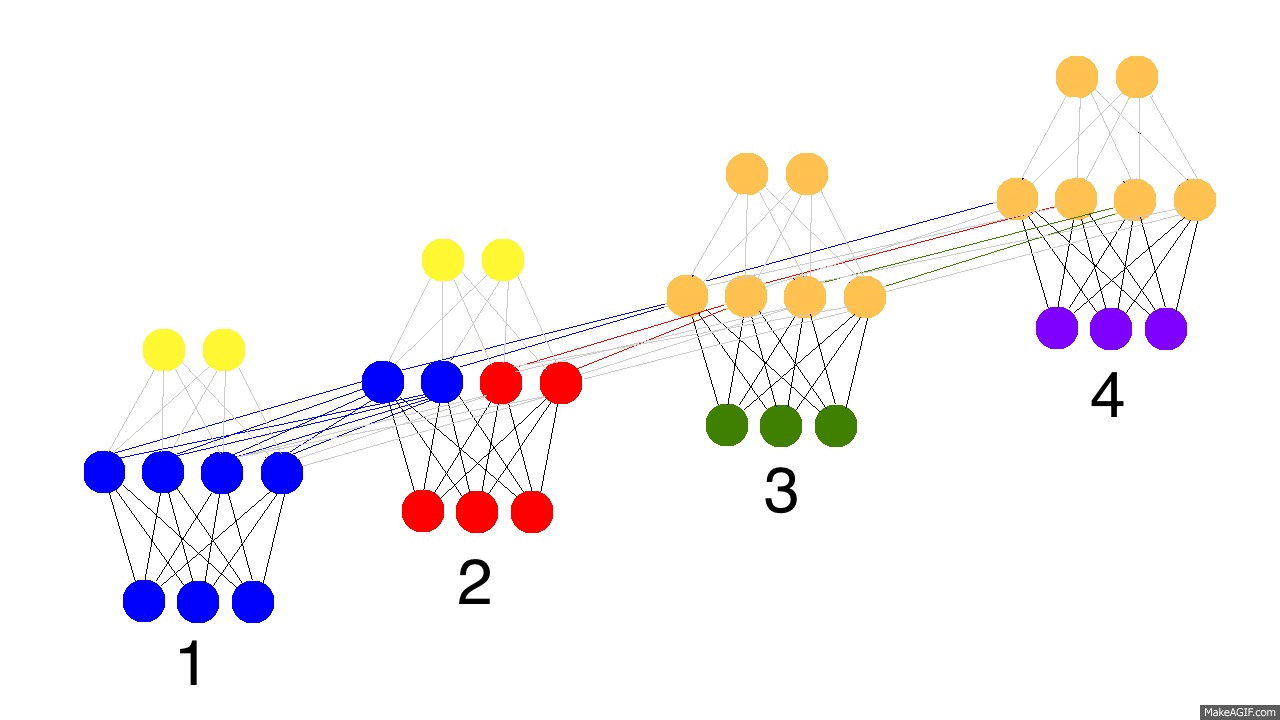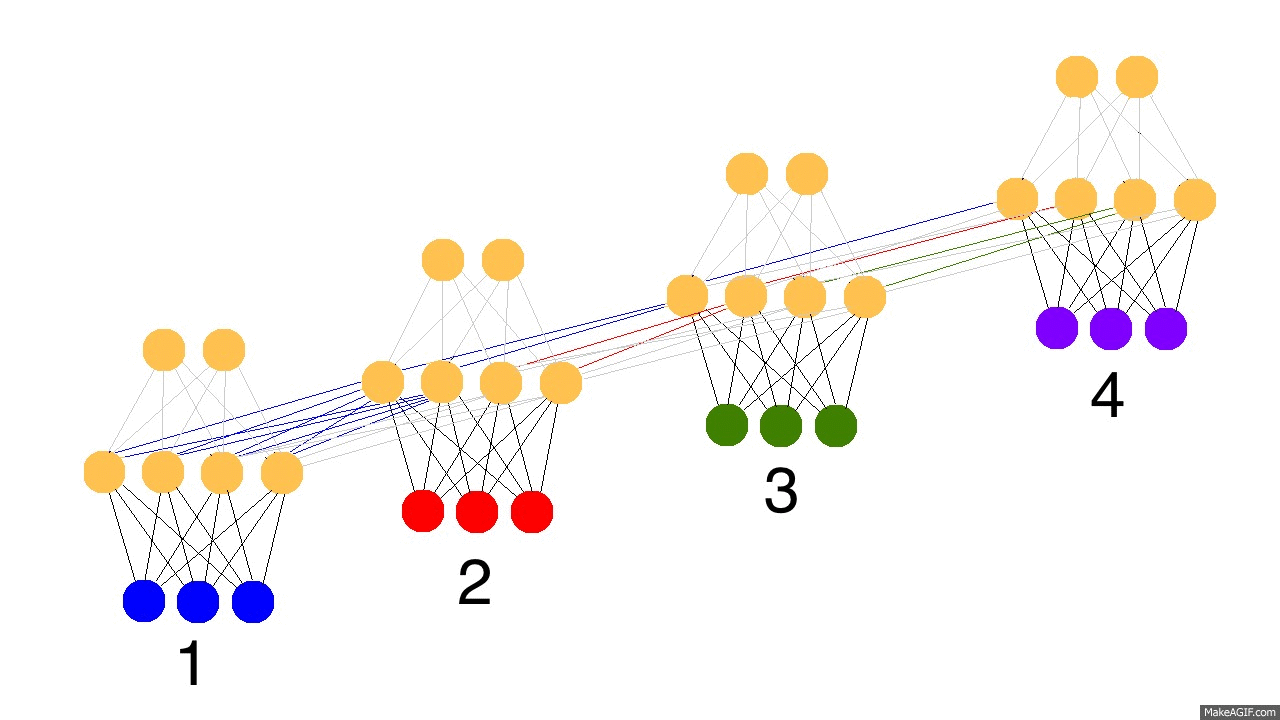
网络通过从1到4的全部前向传播(可以是任意长度的整个序列),然后再从4到1的反向传播导数来学习。你可以把它看成一个有点变形的普通神经网络,除了我们在不同的地方共享权值(synapses 0,1,and h)。除了这点, 它就是一个普通的神经网络。
我们的玩具代码
来,我们用循环神经网络做个模型来实现二进制加法。看到下面的图没,你猜猜顶上的彩色的1表示什么意思呢?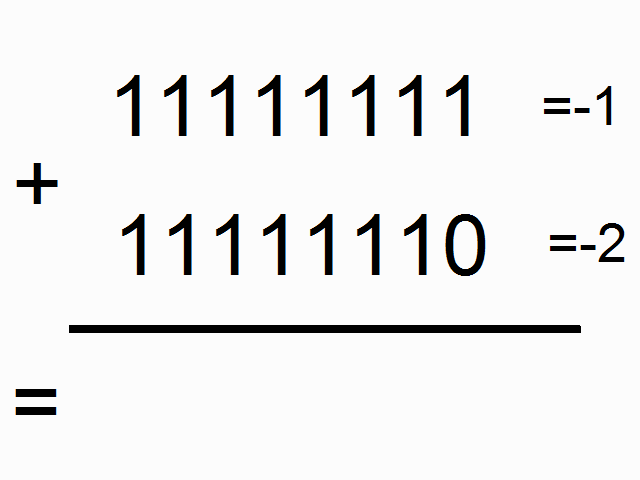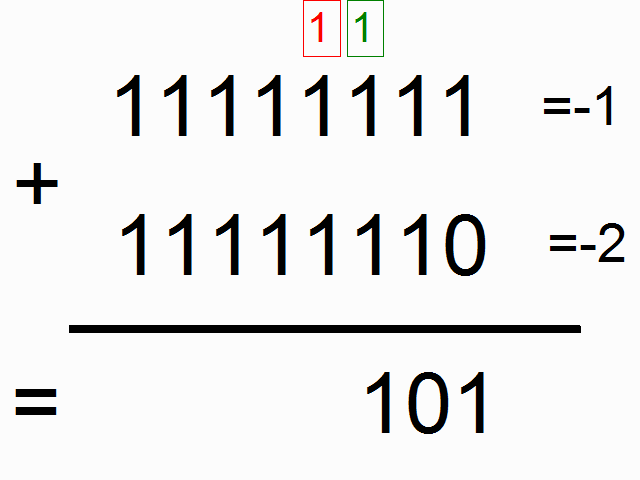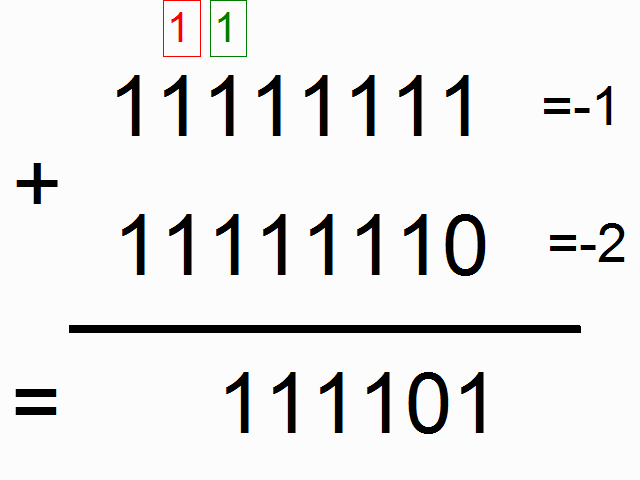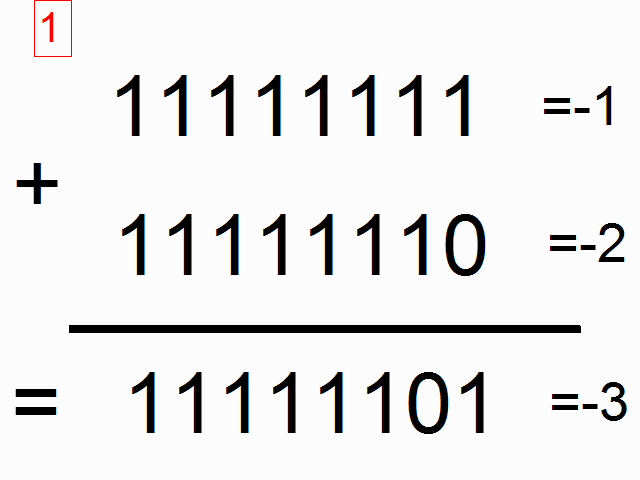
方框里的彩色的1表示进位。我们就要用循环神经网络来记住这个进位。求和的时候需要记住进位(如果不懂,可以看这里)。
二进制加法做法就是,从右往左,根据上面两行的bit来预测第三行的bit为1还是0。我们想要神经网络遍历整个二进制序列记住是否有进位,以便能计算出正确的结果。不要太纠结这个问题本身,神经网络也不在乎这个问题。它在乎的只是每个时刻它会收到两个输入(0或者1),然后它会传递给用于记忆是否有进位的隐藏层。神经网络会把所有这些信息(输入和隐藏层的记忆)考虑进去,来对每一位(每个时间点)做出正确的预测。
下面原文里面是针对每行代码做的注释, 为了方便阅读, 我直接把注释写到了代码里面, 便于大家阅读。
译者注:RNN在自然语言处理里面大量使用,包括机器翻译,对话系统,机器做诗词等,本文只是简单介绍了一下原理。后续我会写一些应用方面的文章,敬请期待。
